 Just My Socks中文教程网
Just My Socks中文教程网
为了方便大家浏览我的小破网站,加速大家的网页打开速度,我斥巨资使用了阿里云CDN,目前使用的是按流量付费的方式。购买的流量包和HTTPS请求包。
流量包价格为20元100G流量,HTTPS请求包是40元1000万次。由于我的网站没有敏感图片,也就没有买鉴黄包。
最近这一周,CDN的消耗速度变得非常不正常,之前基本上是1天1G流量左右,最近突然提高到1天6G左右,按照这样的速度,我的小破钱包就快给这个小破网站买不起流量包了。
其实,我之前有窃喜一阵子的,以为是流量上升了,其实流量只是从800IP提升到了1000IP,流量的消耗却提升了6倍,这明显不正常啊,兄嘚。
所以开始着手,去找出流量消耗的元凶。
确定大致方向:
登陆阿里云控制台之后,进入CDN的管理界面,然后在CDN管理界面的主页,赫然就发现了不正常。(页面右侧还有一个概览,能看到哪个域名下面跑的流量最多)
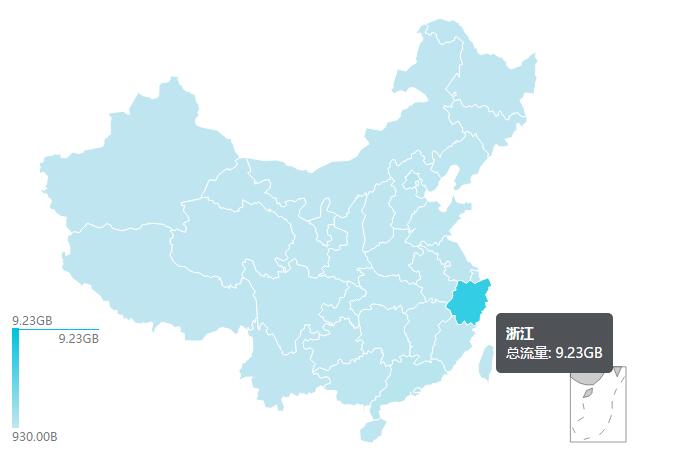
浙江一地的流量消耗了9G+,占了全部CDN流量的70%以上,这明显是不正常的啊。浙江人民是有多喜欢我这个小破网站。
然后点击左侧的监控-->统计分析 查看CDN的各类统计信息
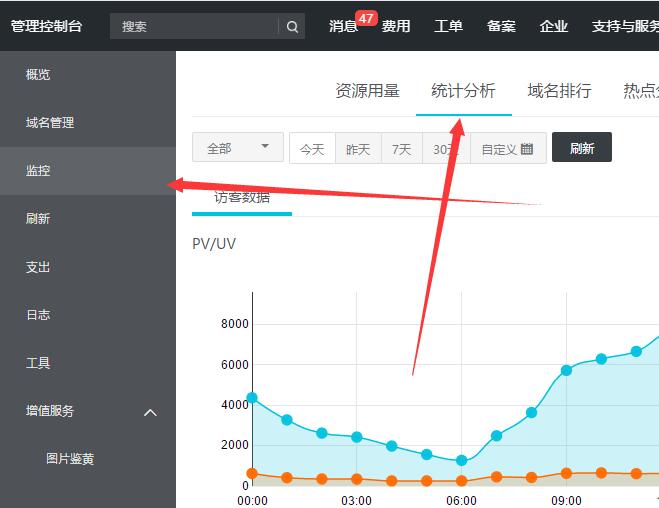
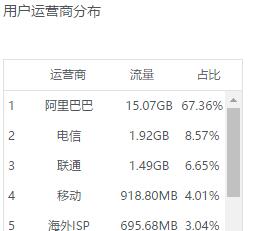
LOOK,在用户运营商分布这个统计里面。阿里巴巴的流量竟然是联通、电信的十几倍!这明显是不正常的,这也说明了,对方的采集爬虫是在阿里云的机器上面。
下面就好揪出采集IP了。
揪出采集爬虫的IP:
还是继续使用阿里云的CDN管理后台。
现在VPS科普网想一想,正常用户一般很少在凌晨时间访问你的网站,而采集爬虫的工作往往是不间断的,爬虫不论时间多么晚,都会来采集你的网站。
所以我打算在凌晨2-3点这个时间段里的log里面找出这个爬虫的IP。
需要注意的是,由于使用了cdn,如果你直接在你的服务器的LOG里找的话,是只能找到阿里云cdn 的ip的,是找不到采集爬虫的真实IP的,这时我们就要使用阿里云的CDN的日志功能。
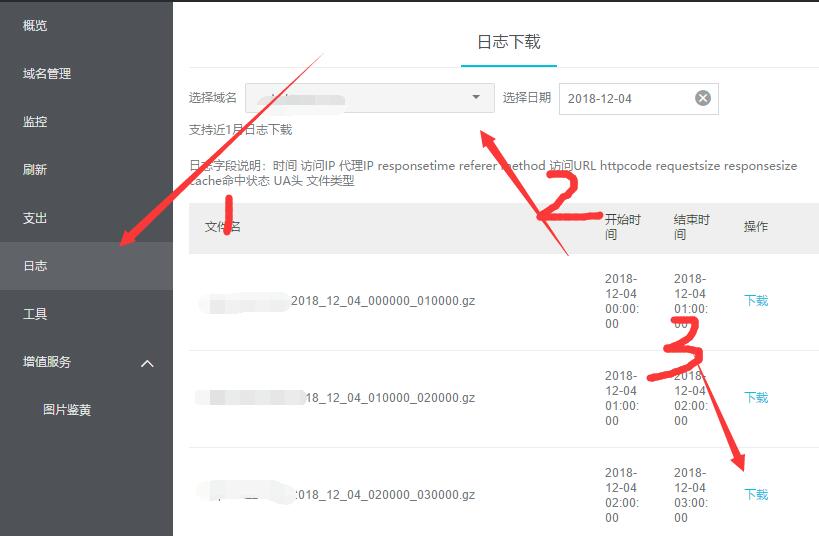
按照如图顺序,先点击日志,然后选择可能性最大的网站,然后下载了凌晨2-3点的日志。
下载解压之后,使用notepad++编辑器打开log文件。
我搭眼一看,就看出了问题。在UA字段,全都是yisouspider。
用CTRL+F 计数一看。在2-3点这个时段里一共470多条访问信息,其中UA是yisouspider的就有450度条。
这就找出了元凶。现在连找IP都不用了,这很明显,是yisouspider这个蜘蛛给爬得。其实我还是看了一下IP的,都是42.开头的,很明显的阿里云杭州机房的IP。
恩,可能是真的yisouspider的蜘蛛,也可能是采集假冒的这个蜘蛛。不过假冒蜘蛛,一般都是假冒百度的蜘蛛。。。
找到元凶之后得继续处理:
按照公开信息显示,yisouspider是神马搜索引擎的蜘蛛,就是UC浏览器的母公司退出的搜索引擎。但是我请教朋友之后,知道yisouspider并不会这么勤奋,尤其是我这个没什么名气的小破网站,不应该爬得这么多。他建议我直接屏蔽这个蜘蛛,不过我本着珍惜每一份流量的想法,还是找到了什么搜索引擎的反馈邮箱,将我的网站的log信息给对方发过去了,让神马搜索引擎的工作人员,帮我看一下,这是真蜘蛛,还是假借蜘蛛的名义采集的。恩,就是这样了。
未经允许不得转载:Just My Socks中文教程网 » 使用阿里云CDN日志功能以寻找采集爬虫的方法


